Labeling Workflow
Plainsight's preferred labeling platform is Encord. The Encord platform provides the fastest way to manage, curate, and annotate AI data.
This document outlines the complete process for creating a new labeling project for image datasets in Encord—from data collection and processing to annotation setup, team handoff, and final delivery to Protege.
Challenges
- Timely Notification — Ensure labeling team leads get advance notice of projects.
- Data Curation — Efficiently process and curate data with GCP and Encord.
- Annotation Consistency — Align annotations with model and filter requirements.
- Training Alignment — Certify labelers via training projects and QA benchmarks.
- Cross-Team Coordination — Smooth handoff between data, annotation, and ML teams.
Our Approach
- Early Notification & Processing — Notify team leads as soon as data lands in GCP.
- Automated & Manual Handling — Use scripts (e.g., data-connectors) + Encord curation.
- Structured Setup — Create datasets, ontologies, and workflows with naming conventions.
- Rigorous Training & Review — Use training sets, guides, and benchmark scoring.
- Clear Handoff Procedures — Email-based communication and checklist handoffs.
Key Components
- Data Processing and Import — Use automation + Encord for import and curation.
- Annotation Project Setup — Ontology creation, dataset linking, and workflow config.
- Training and Handoff — QA projects, guides, and final ML-ready handoff.
Workflow Steps
1. Notification and Data Processing
- Notify team leads about the upcoming labeling project.
- Preprocess data uploaded to GCP as needed.
2. Data Import and Curation in Encord
- Files and Folders — Organize in Encord's File module.
- Import Options — Use the data-connector or bucket integration + manifest script.
- Curation — Use the Explorer tab to filter and finalize files.
References:
3. Dataset and Annotation Project Creation
- Naming Convention:
[client]-[use-case]-[start-date] - Ontology: Ensure alignment with ML and Filter Spec.
- Annotation Project: Link dataset + ontology + workflow. Add Jira ticket in description.
References:
4. (Optional) Create Training Dataset, Benchmark Project & Guide
Use this step for complex or precision-critical labeling.
Training Dataset:
- Use Explorer tab + filters + similarity search + embeddings.
- Select ~2–10 diverse images including outliers.
- Create dataset(s) from collections.
Benchmark Project:
- Set up benchmark in Encord.
- Grades labelers on IoU + classification accuracy.
Labeling Guide:
- Manually label images to build ground truth.
- Create guide using those images (image-first, minimal words).
- Final review/approval by ML engineer.
References:
5. (Optional) Create Training Project
- Create a labeler training project using the benchmark.
- Upload labeling guide, assign team admins and managers.
Reference:
6. Labeling Guide Creation
- Manually label 2–10 images to show standard + edge cases.
- Keep guides image-first with minimal text.
- Final approval by ML engineer.
7. Labeling Workforce Handoff
-
Email Notification — Send Brickred team:
- Project description
- Exam guide
- Clear labeling requirements (with examples)
-
Approval & Setup — After confirmation:
- Add team managers to Training and Annotation Projects.
- Final review of both projects for correctness.
Benefits and Outcomes
- ✅ Streamlined Process — Reduces ambiguity and delay.
- ✅ High Quality — QA processes yield better annotations.
- ✅ Efficient Handoffs — Early notice + docs = faster team ramp-up.
- ✅ Robust Training Data — Improves downstream model accuracy.
Example
Example Labeling Guide
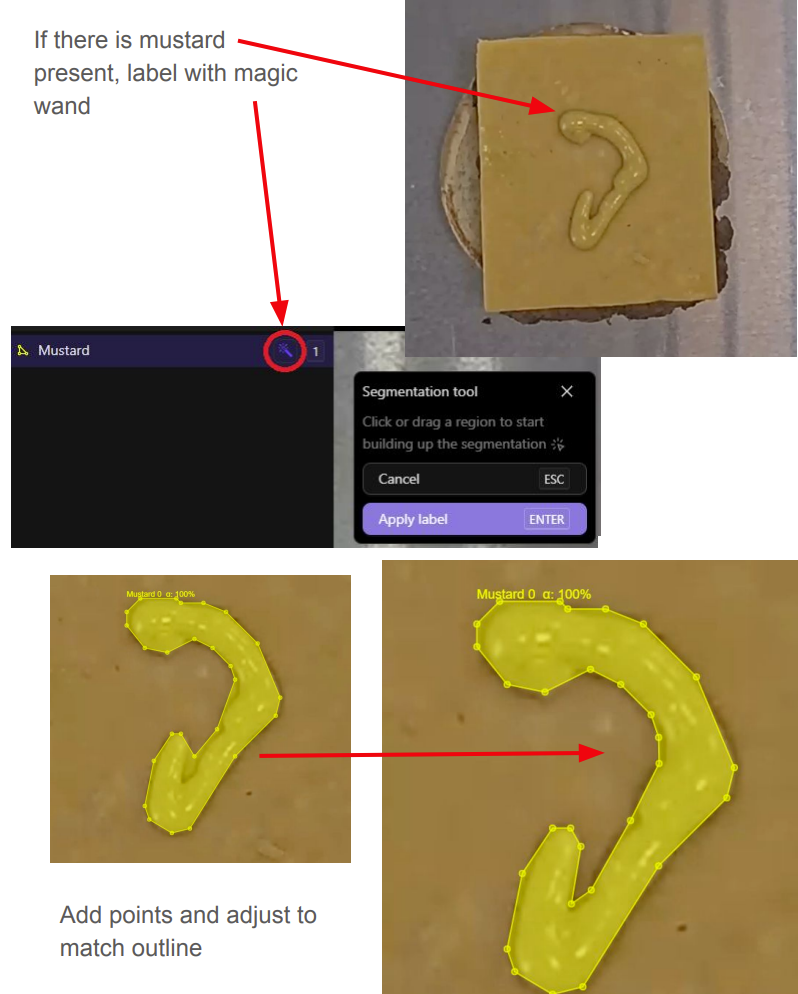
Here’s a real example of a labeling guide used for identifying mustard on burgers:
Next Steps / Recommendations
- Refine Process — Continue iterating based on new project needs.
- Gather Feedback — Include all teams in feedback cycles.
- Update Docs — Keep Label Process Plan, Encord notebooks, and guides up to date.
Conclusion
The Labeling Project Creation workflow offers a structured, repeatable approach for launching new annotation projects. By covering early notifications, data curation, annotation setup, and rigorous training handoff, this process ensures data quality and project efficiency for ML development.